Unlike simple algorithms that treat all objects equally, GDS takes into account:
Size of the object (size(p)): Larger objects take up more space in memory.
Cost of the object (cost(p)): This can represent factors like time to retrieve the object, computational effort, or other resource usage.
Score H(p):
Each key-value pair ppp in the cache is assigned a score H(p). This score reflects the benefit of keeping the object in memory and is calculated using:
A global parameter L, which adjusts dynamically based on cache state.
The size(p) of the object.
The cost(p) associated with the object.
Eviction Strategy:
When the cache is full, and a new object needs to be added, GDS removes the object with the lowest score H(p). This process continues until there is enough space for the new object.
Proposition 1
L is non-decreasing over time.
The global parameter L, which reflects the minimum priority H(p) among all key-value pairs in the KVS, will either stay the same or increase with each operation. This ensures stability and helps prioritize eviction decisions consistently.
For any key-value pair ppp in the KVS, the relationship holds:
L ≤ H(p) ≤ L + cost(p) / size(p)
H(p), the priority of p, always lies between the global minimum L and L + cost(p) / size(p), ensuring H(p) reflects both its retrieval cost and size relative to other elements.
Intuition Behind Proposition 1:
As L increases over time (reflecting the minimum H(p)), less recently used or less “valuable” pairs become increasingly likely to be evicted. This ensures that newer and higher-priority pairs stay in the KVS longer.
Key Insights from Proposition 1:
Delayed Eviction:
When p is requested again while in memory, its H(p) increases to L + cost(p) / size(p), delaying its eviction.
Impact of Cost-to-Size Ratio:
Pairs with higher cost(p) / size(p) stay longer in the KVS. For example, if one pair’s ratio is c times another’s, it will stay approximately c times longer.
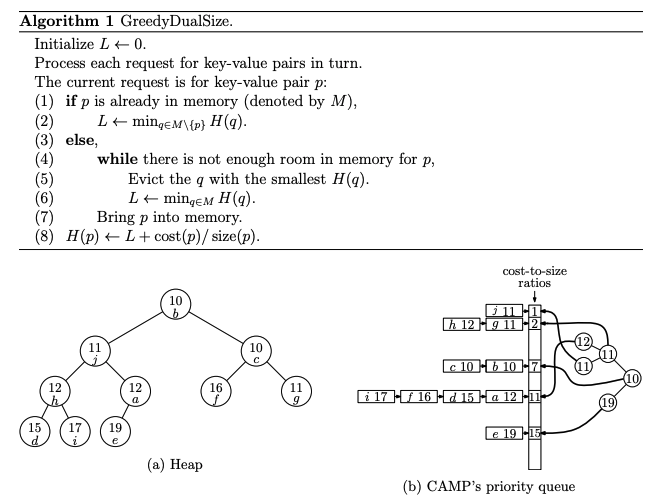
Key Points in the Diagram
Cost-to-Size Ratios:
Key-value pairs are grouped into queues according to their cost-to-size ratio.
Each queue corresponds to a specific cost-to-size ratio.
Grouping by Ratio:
Within each queue, key-value pairs are managed using the Least Recently Used (LRU) strategy.
Priority Management:
The priority (H-value) of a key-value pair is based on: H(p) = L + cost(p) / size(p)
L: The global non-decreasing variable.
cost(p) / size(p): The cost-to-size ratio of the key-value pair.
Efficient Eviction:
CAMP maintains a heap that points to the head of each queue, storing the minimum H(p) from every queue.
To identify the next key-value pair for eviction:
The algorithm checks the heap to find the queue with the smallest H(p).
It then evicts the key-value pair at the front of that queue (i.e., the least recently used pair in that cost-to-size group).
Rounding in CAMP
Purpose: To improve performance, CAMP reduces the number of LRU queues by grouping key-value pairs with similar cost-to-size ratios into the same queue.
Key Idea: Preserve the most significant bits proportional to the value’s size.
Proposition 2: Explanation of Rounding and Distinct Values
Implications
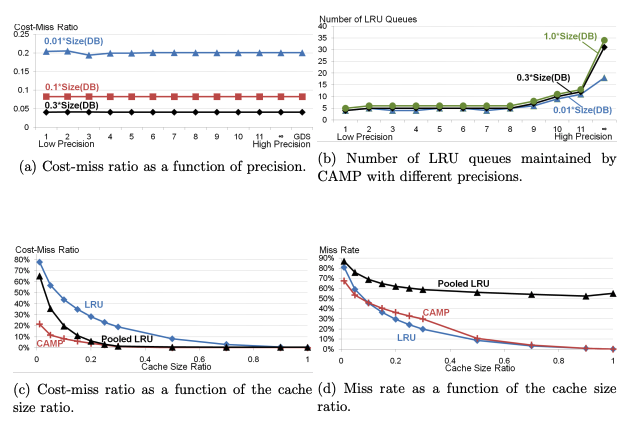
Trade-Off Between Precision and Efficiency:
A higher p preserves more precision but increases the number of distinct values (and thus computational complexity).
Lower p reduces the number of distinct values, making CAMP more efficient but less precise.
Rounding Efficiency:
By limiting the number of distinct values, CAMP minimizes the number of LRU queues, reducing overhead while still approximating GDS closely.
Proposition 3: Competitive Ratio of CAMP
Practical Implications
Precision ppp:
The smaller the ϵ (higher ppp), the closer CAMP approximates GDS.
For sufficiently large p, CAMP performs nearly as well as GDS.
Trade-off:
Higher p increases precision but also increases the number of distinct cost-to-size ratios and computational overhead.
CAMP’s Improvement Over GDS:
Approximation: CAMP simplifies H(p) by rounding the cost-to-size ratio, reducing the precision but making the algorithm more efficient.
Grouping: Key-value pairs are grouped by similar cost-to-size ratios, reducing the number of queues and simplifying priority management.
Tie-Breaking: CAMP uses LRU within each group to determine the eviction order, making it computationally cheaper.
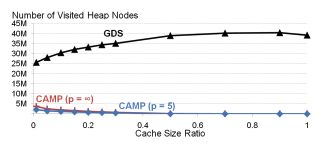
Figure 4: Heap Node Visits
This figure compares the number of heap node visits for GDS and CAMP as a function of cache size:
GDS:
Heap size equals the total number of key-value pairs in the cache.
Every heap update (insertion, deletion, or priority change) requires visiting O(logn) nodes, where n is the number of cache entries.
As cache size increases, GDS’s overhead grows significantly.
CAMP:
Heap size equals the number of non-empty LRU queues, which is much smaller than the total number of cache entries.
Heap updates occur only when:
The priority of the head of an LRU queue changes.
A new LRU queue is created.
As cache size increases, the number of non-empty LRU queues remains relatively constant, resulting in fewer heap updates.
What is the time complexity of LRU to select a victim?
O(1) because the least recently used item is always at the tail of the list.
What is the time complexity of CAMP to select a victim?
O(logk) CAMP identifies the key-value pair with the smallest priority from the heap, deletes it and then heapifies.
Why does CAMP do rounding using the high order bits?
CAMP rounds cost-to-size ratios to reduce the number of distinct ratios (or LRU queues).
High-order bits are retained because they represent the most significant portion of the value, ensuring that approximate prioritization is maintained.
How does BG generate social networking actions that are always valid?
Pre-Validation of Actions:
Before generating an action, BG checks the current state of the database to ensure the action is valid. For instance:
A friend request is only generated if the two users are not already friends or in a “pending” relationship.
A comment can only be posted on a resource if the resource exists.
Avoiding Concurrent Modifications:
BG prevents multiple threads from concurrently modifying the same user’s state.
How does BG scale to a large number of nodes?
BG employs a shared-nothing architecture with the following mechanisms to scale effectively:
Partitioning Members and Resources:
BGCoord partitions the database into logical fragments, each containing a unique subset of members, their resources, and relationships.
These fragments are assigned to individual BGClients.
Multiple BGClients:
Each BGClient operates independently, generating workloads for its assigned logical fragment.
By running multiple BGClients in parallel across different nodes, BG can scale horizontally to handle millions of requests.
D-Zipfian Distribution:
To ensure realistic and scalable workloads, BG uses a decentralized Zipfian distribution (D-Zipfian) that dynamically assigns requests to BGClients based on node performance.
Faster nodes receive a larger share of the logical fragments, ensuring even workload distribution.
Concurrency Control:
BG prevents simultaneous threads from issuing actions for the same user, maintaining the integrity of modeled user interactions and avoiding resource contention.
True or False: BG quantifies the amount of unpredictable data produced by a data store?
True.
This is achieved through:
Validation Phase:
BG uses read and write log records to detect instances where a read operation observes a value outside the acceptable range, classifying it as “unpredictable data.”
Metrics Collection:
The percentage of requests that observe unpredictable data (τ) is a key metric used to evaluate the data store’s consistency.
How is BG’s SoAR different than its Socialites rating?
SoAR (Social Action Rating): Represents the maximum throughput (actions per second) a data store can achieve while meeting a given SLA.
Socialites Rating: Represents the maximum number of concurrent threads(users) a data store can support while meeting the SLA.
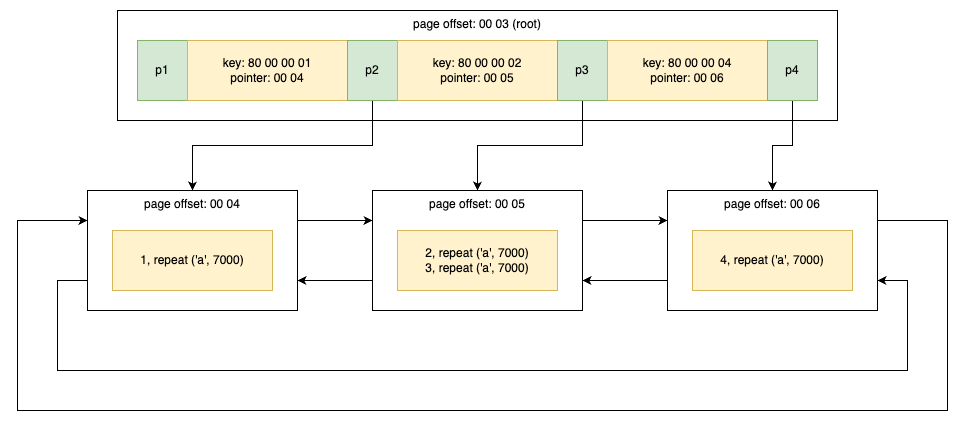
工作线程取任务:每个工作线程从队列中取出一个 Range,如粒度过大(分片数 > 线程数)则再基于该 RANGE 的键值范围按同样方式二次切分,然后依次扫描该范围内的记录,通过内部函数 row_search_mvcc 获取每条记录并执行回调(如计数或检查)。
结果汇总:各线程扫描完毕后,用户线程收集各子树的统计结果或校验结果,并返回给 SERVER 层。
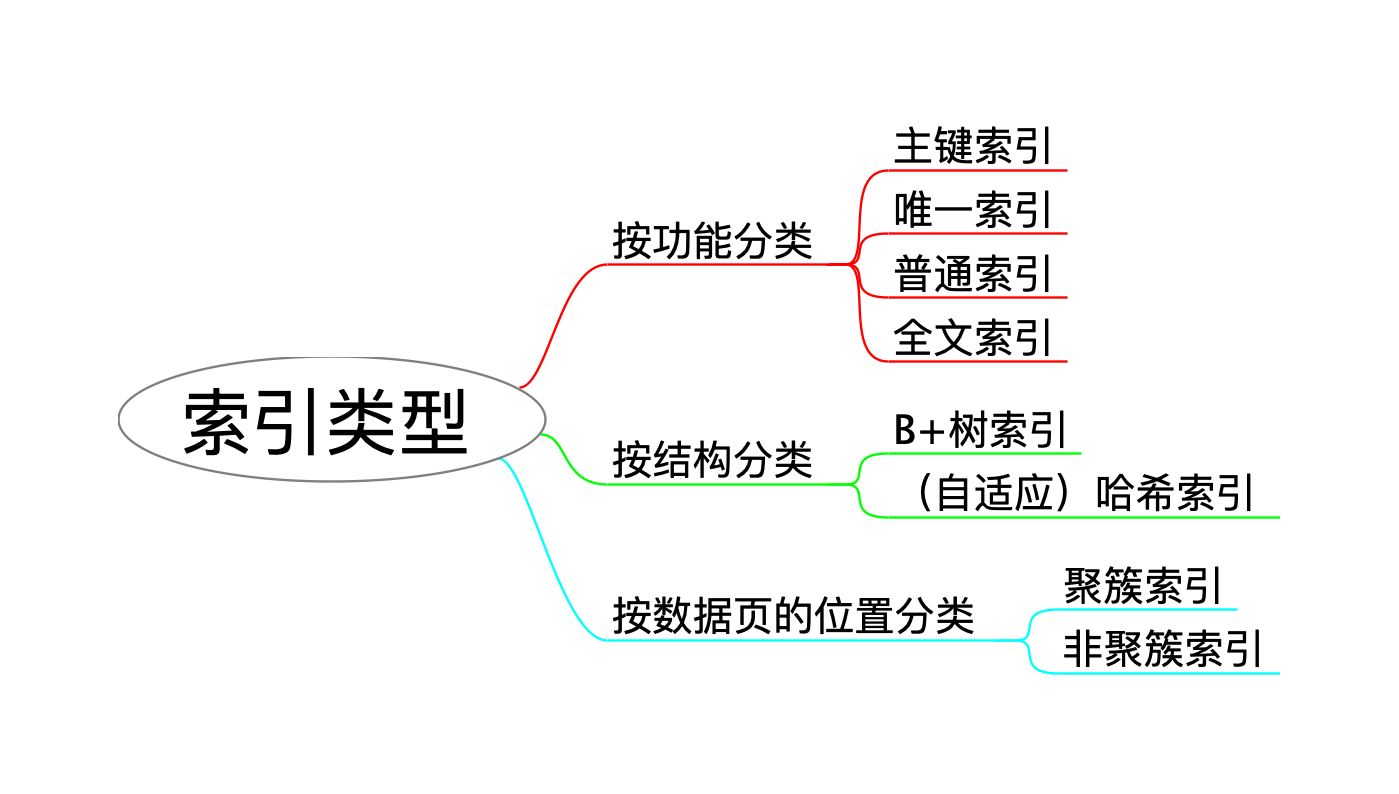
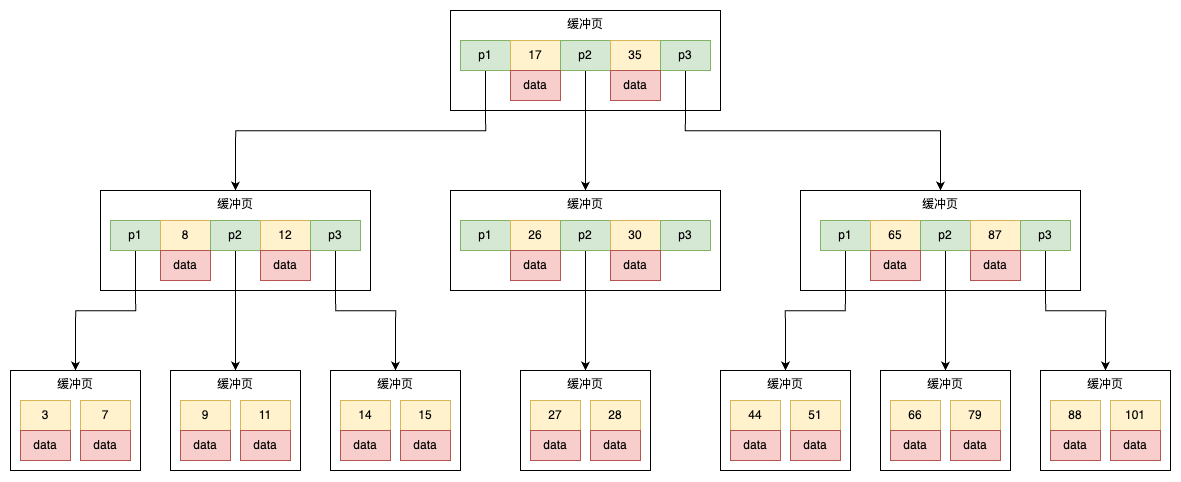
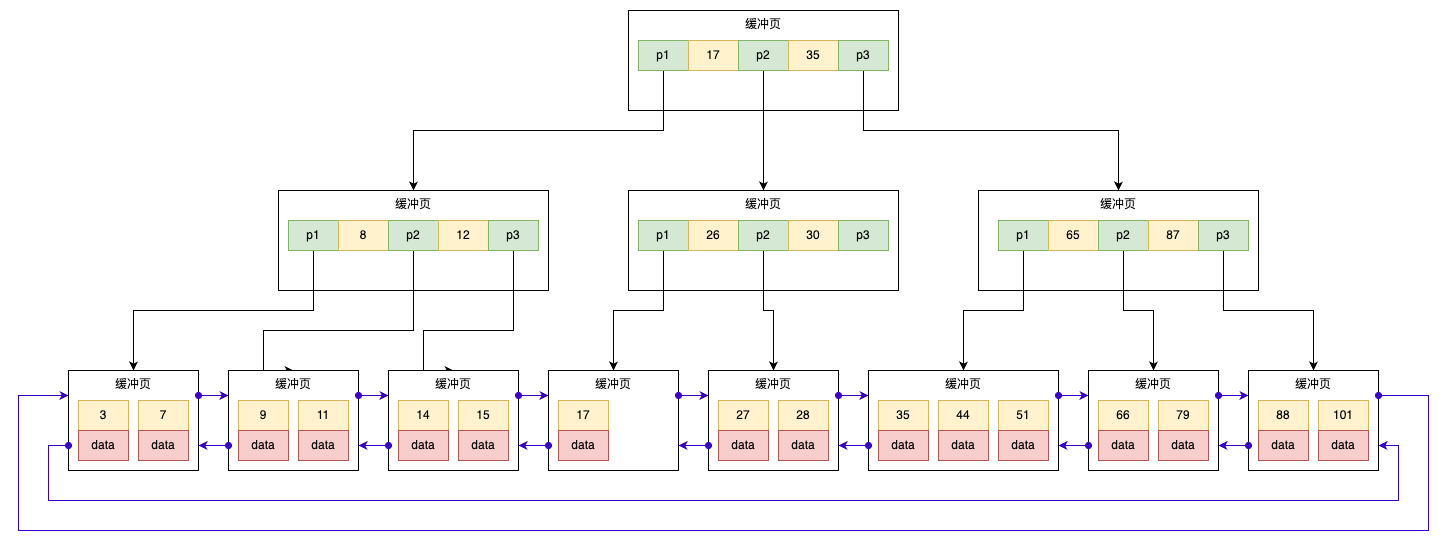
分片(Sharding)机制
并行扫描将 B+ 树划分为多个子树,每个子树对应一个 RANGE 结构体:
1 2 3 4
structRANGE { Iter start; // 子树起始记录位置 Iter end; // 子树结束记录位置(右开区间) };
其中 Iter 包含了记录指针和 B+ 树游标,用于定位扫描边界。工作线程可对粒度过大的 Range 再次细分,以提高负载均衡。
Iter 的结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
/** Boundary of the range to scan. */ structIter { /** Destructor. */ ~Iter(); /** Heap used to allocate m_rec, m_tuple and m_pcur. */ mem_heap_t *m_heap{}; // 分配迭代所需内存(记录副本、tuple、游标等) /** m_rec column offsets. */ const ulint *m_offsets{}; // 原始记录中各列的偏移数组 /** Start scanning from this key. Raw data of the row. */ constrec_t *m_rec{}; // 指向边界记录的原始数据 /** * Tuple representation inside m_rec, * for two Iter instances in a range m_tuple will be [first->m_tuple, second->m_tuple). */ constdtuple_t *m_tuple{}; // m_rec 对应的解析后 tuple,方便按列访问 /** Persistent cursor. */ btr_pcur_t *m_pcur{}; // 用于快速定位 m_rec 所在页的 B+ 树游标 };
字段说明
m_heap:用于在堆上分配和管理该 Iter 所需的临时内存,包括存放记录副本、tuple 结构和游标状态等。
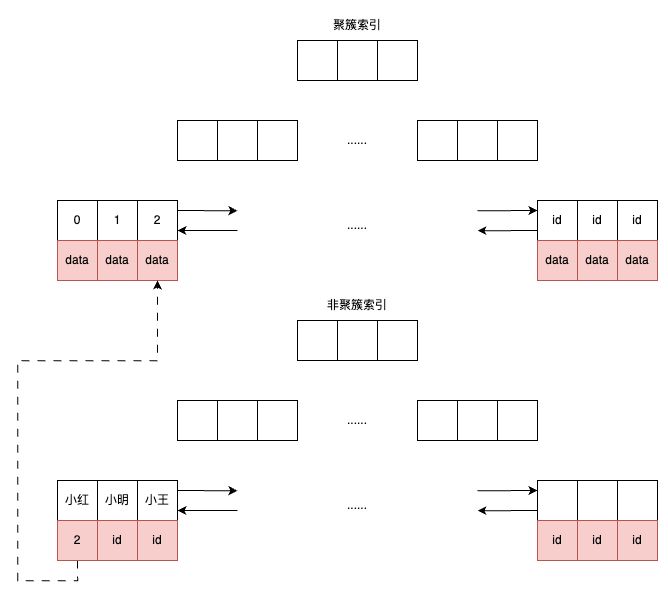
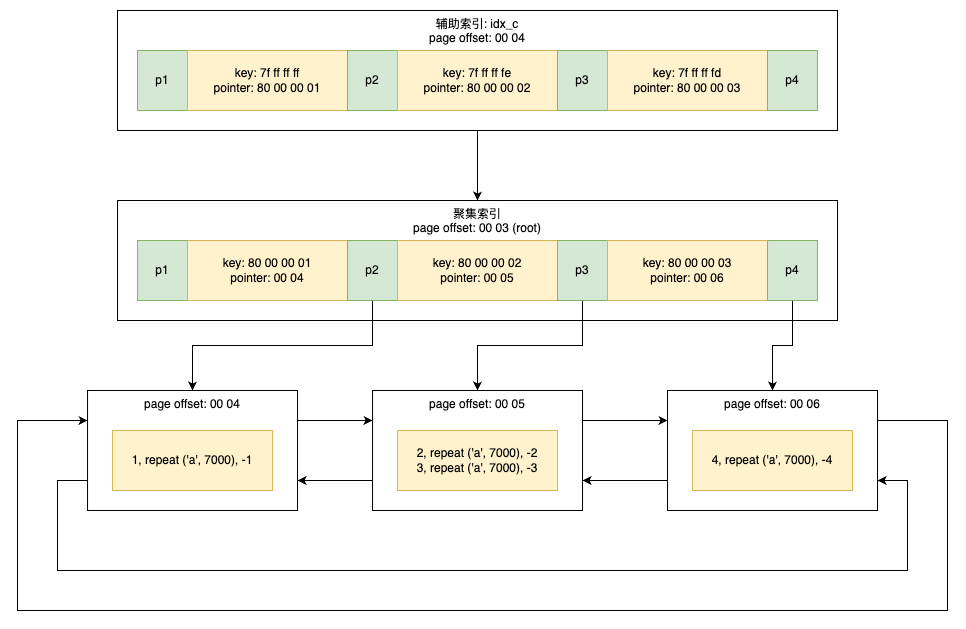
CREATE TABLE t ( a INTNOT NULL, b VARCHAR(8000), c INTNOT NULL, PRIMARY KEY (a), KEY idx_c (c) ) ENGINE=InnoDB;
INSERT INTO t SELECT1, REPEAT('a', 7000), -1; INSERT INTO t SELECT2, REPEAT('a', 7000), -2; INSERT INTO t SELECT3, REPEAT('a', 7000), -3; INSERT INTO t SELECT4, REPEAT('a', 7000), -4;
InnoDB 存储引擎从 InnoDB 1.0.x 版本开始支持一种称为 Fast Index Creation(快速索引创建) 的索引创建方式——简称 FIC。
对于辅助索引的创建,InnoDB 存储引擎会对创建索引的表加上一个 S 锁。在创建的过程中,不需要重建表,因此速度较之前提高很多,并且数据库的可用性也得到了提高。 删除辅助索引操作就更简单了,InnoDB 存储引擎只需更新内部视图,并将辅助索引的空间标记为可用,同时触发 MySQL 数据库内部视图上对该索引定义即可以。
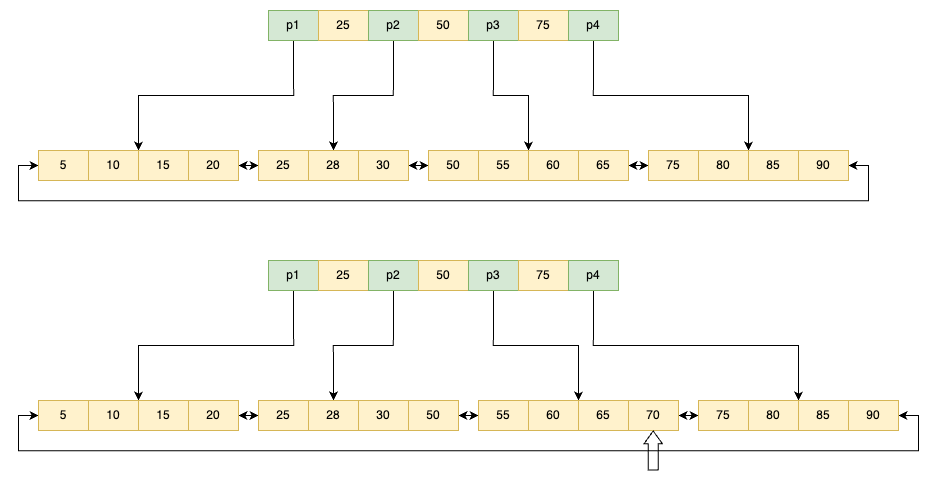
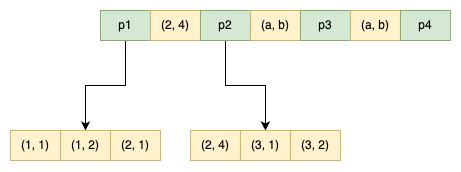
CREATE TABLE t ( a INT, b INT, PRIMARY KEY (a), KEY idx_a_b (a, b) ) ENGINE=INNODB;
该表对应的联合索引结构如下(同样省去叶节点之间的指针):
因此,对于查询 SELECT * FROM TABLE WHERE a=xxx and b=xxx,显然是可以使用 (a, b) 这个联合索引的。对于单个 a 列查询 SELECT * FROM TABLE WHERE a=xxx,也可以使用这个 (a, b) 索引。但对于 b 列的查询 SELECT * FROM TABLE WHERE b=xxx,则不可以使用这棵 B+ 树索引。可以发现叶子节点上的 b 值为 1、2、1、4、1、2,显然不是排序的,因此对于 b 列的查询使用不到 (a, b) 的索引。
MySQL 数据库会在取出索引的同时判断是否可以进行 WHERE 条件的过滤,也就是将 WHERE 的部分过滤操作放在了存储引擎层。在某些查询下,可以大大减少上层 SQL 层对记录的索取,从而提高数据库的整体性能。
Index Condition Pushdown 优化支持 range、ref、eq_ref、ref_or_null 类型的查询,当前支持 MyISAM 和 InnoDB 存储引擎。当优化器选择 Index Condition Pushdown 优化时,可在执行计划的 Extra 列看到 Using index condition 提示。
SELECT*FROM people WHERE zipcode ='95054' AND lastname LIKE'%etrunia%' AND address LIKE'%Main Street%';
对于上述语句,MySQL 数据库可以通过索引定位 zipcode = '95054' 的记录,但是索引对 WHERE 条件的 lastname LIKE '%etrunia%' 和 address LIKE '%Main Street%' 没有任何帮助。若不支持 Index Condition Pushdown 优化,则数据库需要先通过索引取出所有 zipcode = '95054' 的记录,然后再对这部分记录执行 lastname LIKE '%etrunia%' AND address LIKE '%Main Street%' 的过滤,才能最终得到结果。
若支持 Index Condition Pushdown 优化,则在索引扫描阶段,MySQL 存储引擎会先判断 zipcode = '95054' 这一部分(因为这是索引的第一列条件),然后在“取出”符合该索引前缀的行时,立即在存储引擎层对 lastname LIKE '%etrunia%' AND address LIKE '%Main Street%' 这两个条件进行过滤,只把同时满足三个条件的记录交给上层 SQL 层做最终读取。这样就极大地减少了上层 SQL 层对行的 fetch 次数,从而提高查询效率。当然,WHERE 中被下推的条件必须是“索引范围能够覆盖到”的列,否则无法下推。例如 lastname LIKE '%abc%' 或者 address LIKE '%xyz%' 带有前缀通配符(前面有 %),在大多数情况下并不属于索引可下推的范围;只有当索引是覆盖该列并且能够使用“范围扫描”或“等值比较”时,条件下推才有效。
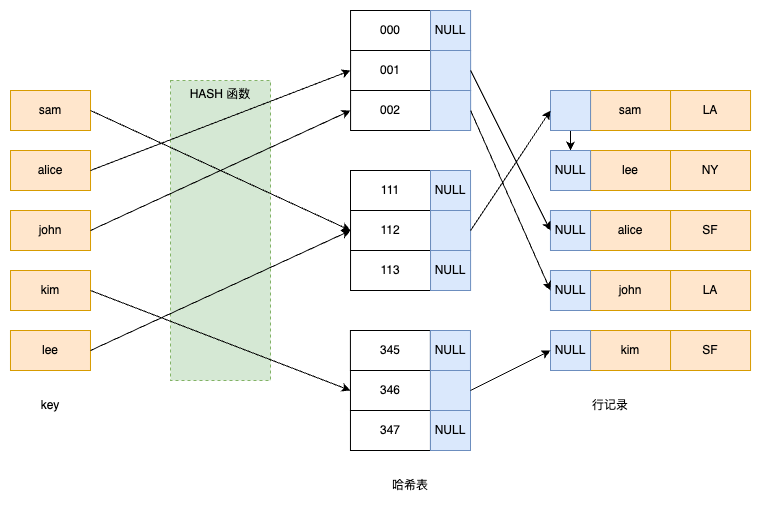
InnoDB 中的哈希算法
哈希表基本结构与冲突解决
InnoDB 在缓冲池中维护一个哈希表,用于物理页号 → 缓冲池页地址的快速映射。
哈希冲突时采用链表方式:每个缓冲池页有一个指向同一哈希值下链上下一个页的指针,形成冲突链。
哈希函数:除法散列法(Division Method)
InnoDB 选取的哈希函数为 除法散列,即: $hash_value = K mod m$ 其中,
参数文件:告诉 MySQL 实例启动时在哪里可以找到数据库文件,并且指定某些初始化参数,这些参数定义了某种内存结构的大小等设置,还会介绍各种参数的类型。
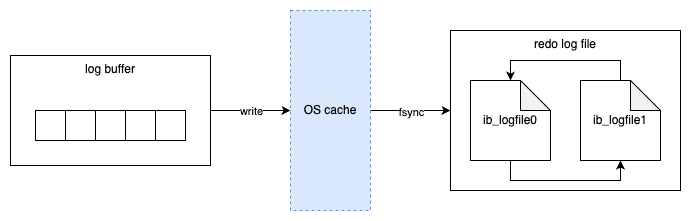
日志文件:用来记录 MySQL 实例对某种条件做出响应时写入的文件,如错误日志文件、二进制日志文件、慢查询日志文件、查询日志文件等。
socket 文件:当用 UNIX 域套接字方式进行连接时需要的文件。
pid 文件:MySQL 实例的进程 ID 文件。
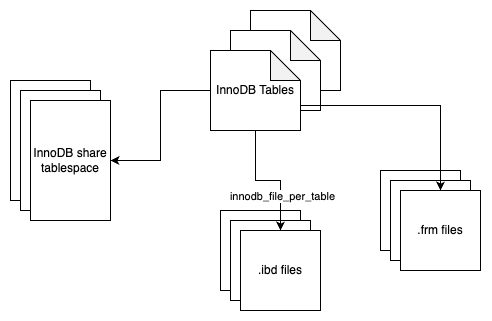
MySQL 表结构文件:用来存放 MySQL 表结构定义文件。
存储引擎文件:由于 MySQL 表存储引擎的关系,每个存储引擎都会有自己的文件来保存各种数据。这些存储引擎真正存储了记录和索引等数据。本章主要介绍与 InnoDB 有关的存储引擎文件。
参数文件
当 MySQL 实例启动时,数据库会先去读一个配置参数文件,用来寻找数据库的各种文件所在位置以及指定某些初始化参数,这些参数通常定义了某种内存结构有多大等。在默认情况下,MySQL 实例会按照一定的顺序在指定的位置进行读取,用户只需通过命令 mysql –help | grep my.cnf 来寻找即可。
MySQL 实例可以不需要参数文件,这时所有的参数值取决于编译 MySQL 时指定的默认值和源代码中指定参数的默认值。但是,如果 MySQL 实例在默认的数据库库目录下找不到 mysql 系统数据库,则启动同样会失败。
参数类型
MySQL 数据库中的参数可以分为两类:
动态(dynamic)参数
静态(static)参数
动态参数意味着可以在 MySQL 实例运行中进行更改,静态参数说明在整个实例生命周期内都不得进行更改,就好像是只读(read only)的。可以通过 SET 命令对动态参数值进行修改,SET 的语法如下:
二进制日志文件的文件格式为二进制(好像有点废话),不能像错误日志文件、慢查询日志文件那样用 cat、head、tail 等命令来看查看。要查看二进制日志文件的内容,必须通过 MySQL 提供的工具 mysqlbinlog。
示例:
执行的 SQL 为:UPDATE users SET age = age + 1 WHERE id = 100;
binlog_format=STATEMENT 时的 binlog 输出(可读):
1 2 3 4
# at 234 #240523 15:00:01 server id 1 end_log_pos 345 Query thread_id=7 exec_time=0 error_code=0 SET TIMESTAMP=1716495601/*!*/; UPDATE users SET age = age + 1 WHERE id = 100/*!*/;
binlog_format=ROW 时的 binlog 输出(不可读):
1 2 3 4 5 6 7 8 9 10 11
# at 456 #240523 15:00:02 server id 1 end_log_pos 567 Table_map: `test`.`users` mapped to number 108 # at 567 #240523 15:00:02 server id 1 end_log_pos 678 Update_rows: table id 108 flags: STMT_END_F ### UPDATE `test`.`users` ### WHERE ### @1=100 /* id */ ### @2=20 /* age (原值) */ ### SET ### @1=100 ### @2=21 /* age (新值) */
ER Diagram (Figure 1.a):Represents entities and relationships in the BG system.
Member Entity:
Represents users with a registered profile, including a unique ID and a set of adjustable-length string attributes to create records of varying sizes.
Each user can have up to two images:
Thumbnail Image: Small (in KBs), used for displaying in friend lists.
High-Resolution Image: Larger (hundreds of KBs or MBs), displayed when visiting a user profile.
Using thumbnails significantly reduces system load compared to larger images.
Friend Relationship:
Captures relationships or friend requests between users. An attribute differentiates between invitations and confirmed friendships.
Resource Entity:
Represents user-owned items like images, questions, or documents. Resources must belong to a user and can be posted on their profile or another user’s profile.
Manipulation Relationship:
Manages comments and restrictions (e.g., only friends can comment on a resource).
BG Workload and SLA (Service-Level Agreement)
Workload: BG supports defining workloads at the granularity of:
Actions: Single operations like “view profile” or “list friends.”
Sessions: A sequence of related actions (e.g., browsing a profile, sending a friend request).
Mixed Workloads: A combination of actions and sessions.
Service-Level Agreement (SLA):
Goal: Ensures the system provides reliable performance under specified conditions.
Example SLA Requirements: SLA, e.g., 95% of requests to observe a response time equal to or faster than 100 msec with at most 0.1% of requests observing unpredictable data for 10 minutes.
Metrics:
SoAR (Social Action Rating): Measures the highest number of actions per second that meet the SLA.
Socialites: Measures the maximum number of concurrent threads that meet the SLA, reflecting the system’s multithreading capabilities.
Performance Evaluation Example
SQL-X System Performance:SQL-X is a relational database with strict ACID compliance.
Initially, throughput increases with more threads.
Beyond a certain threshold (e.g., 4 threads), request queuing causes response times to increase, reducing SLA compliance.
With 32 threads, 99.94% of requests exceed the 100-millisecond SLA limit, indicating significant performance degradation.
Concurrency and Optimization in BG
Concurrency Management:
BG prevents two threads from emulating the same user simultaneously to realistically simulate user behavior.
Unpredictable Data Handling:
Definition: Data that is stale, inconsistent, or invalid due to system limitations or race conditions.
Validation:
BG uses offline validation to analyze read and write logs.
It determines acceptable value ranges for data and flags any reads that fall outside these ranges as unpredictable.
If SoAR is zero, the data store fails to meet SLA requirements, even with a single-threaded BGClient issuing requests.
Actions
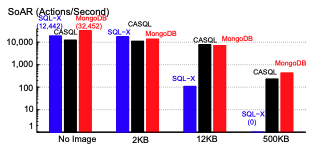
Performance Analysis of View Profile
Performance of VP is influenced by whether profile images are included and their sizes.
Experiment Setup:
Profile data tested with:
No images.
2 KB thumbnails combined with profile images of 2 KB, 12 KB, and 500 KB sizes.
Metrics: SoAR (Social Action Rating) measures the number of VP actions per second that meet the SLA (response time ≤ 100 ms).
Results:
No Images:
MongoDB performed the best, outperforming SQL-X and CASQL by almost 2x.
12 KB Images:
SQL-X’s SoAR dropped significantly, from thousands of actions per second to only hundreds.
500 KB Images:
SQL-X failed to meet the SLA (SoAR = 0) because transmitting large images caused significant delays.
MongoDB and CASQL also experienced a decrease in SoAR but performed better than SQL-X.
Role of CASQL:
CASQL outperformed SQL-X due to its caching layer (memcached):
During a warm-up phase, 500,000 requests populate the cache with key-value pairs for member profiles.
Most requests are serviced by memcached instead of SQL-X, significantly improving performance with larger images (12 KB and 500 KB).
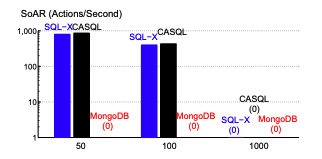
Performance Analysis of List Friends
1. SQL-X
Process:
Joins the Friends table with the Members table to fetch the friend list.
Friendship between two members is represented as a single record in the Friends table.
Performance:
When ϕ (number of friends) is 1000, SQL-X struggles due to the overhead of joining large tables and fails to meet SLA requirements.
2. CASQL
Process:
Uses a memcached caching layer to store and retrieve results of the LF action.
Results are cached as key-value pairs.
Performance:
Outperforms SQL-X when ϕ is 50 or 100 by a small margin (<10% improvement).
At ϕ=1000, memcached’s key-value size limit (1 MB) causes failures, as the data exceeds this limit.
Adjusting memcached to support larger key-value pairs (e.g., 2 MB for 1000 friends with 2 KB thumbnails) could improve performance.
3. MongoDB
Process:
Retrieves the confirmedFriends array from the referenced member’s document.
Can fetch friends’ profile documents one by one or as a batch.
Performance:
Performs no joins, but its SLA compliance is poor for larger friend counts.
SoAR is zero for ϕ=50,100,1000, as it fails to meet the 100 ms response time requirement.
For smaller friend lists (ϕ=10), MongoDB achieves a SoAR of 6 actions per second.
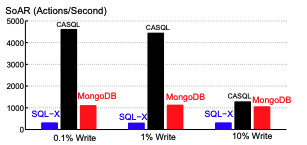
Mix of Read and Write Actions
Purpose: Evaluates the performance of data stores under different ratios of read and write operations.
Categories:
Read actions: Include operations like View Profile (VP), List Friends (LF), and View Friend Requests (VFR).
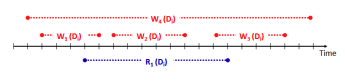
Definition: Data that is stale, inconsistent, or invalid, produced due to race conditions, dirty reads, or eventual consistency.
BG’s Validation Process
Validation Implementation
Log Generation:
BG generates read log records (observed values) and write log records (new or delta values).
Offline Validation:
For each read log entry:
BG computes a range of valid values using overlapping write logs.
If the observed value is outside this range, it is flagged as unpredictable.
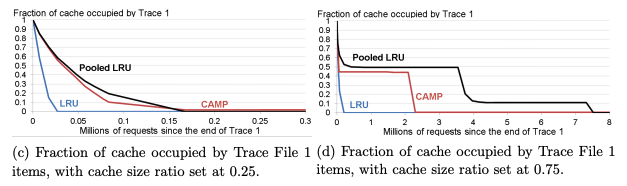
Impact of Time-to-Live (TTL) on Unpredictable Data
Results:
Higher TTL Increases Stale Data:
A higher TTL (e.g., 120 seconds) results in more stale key-value pairs, increasing the percentage of unpredictable data.
For T=100T = 100T=100, unpredictable data is:
~79.8% with TTL = 30 seconds.
~98.15% with TTL = 120 seconds.
Performance Trade-off:
A higher TTL improves performance (fewer cache invalidations) but increases stale data.
Lower TTL reduces stale data but impacts cache performance.
Heuristic Search for Rating
Why Use Heuristic Search?
Exhaustive search starting from T=1 to the maximum T is time-consuming.
MongoDB with T=1000 and Δ=10 minutes would take 7 days for exhaustive testing.
Steps in Heuristic Search:
Doubling Strategy:
Start with T=1, double T after each successful experiment.
Stop when SLA fails, narrowing down T to an interval.
Binary Search:
Identify the T corresponding to max throughput within the interval.
Used for both SoAR (peak throughput) and Socialites (maximum concurrent threads).
Questions
What system metrics does BG quantify?
SoAR (Social Action Rating):
The highest throughput (actions per second) that satisfies a given SLA, ensuring at least α% of requests meet the response time β, with at most τ% of requests observing unpredictable data.
Socialites Rating:
The maximum number of simultaneous threads (or users) that a data store can support while still meeting the SLA requirements.
Throughput:
Total number of completed actions per unit of time.
Response Time:
Average or percentile-based latency for each action.
Unpredictable Data:
The percentage of actions that observe stale, inconsistent, or invalid data during execution.
How does BG scale to generate a large number of requests?
BG employs a shared-nothing architecture with the following mechanisms to scale effectively:
Partitioning Members and Resources:
BGCoord partitions the database into logical fragments, each containing a unique subset of members, their resources, and relationships.
These fragments are assigned to individual BGClients.
Multiple BGClients:
Each BGClient operates independently, generating workloads for its assigned logical fragment.
By running multiple BGClients in parallel across different nodes, BG can scale horizontally to handle millions of requests.
D-Zipfian Distribution:
To ensure realistic and scalable workloads, BG uses a decentralized Zipfian distribution (D-Zipfian) that dynamically assigns requests to BGClients based on node performance.
Faster nodes receive a larger share of the logical fragments, ensuring even workload distribution.
Concurrency Control:
BG prevents simultaneous threads from issuing actions for the same user, maintaining the integrity of modeled user interactions and avoiding resource contention.
If two modeled users, A and B, are already friends, does BG generate a friend request from A to B?
No, BG does not generate a friend request from A to B if they are already friends.
Before generating a friend request, BG validates whether the relationship between A and B is pending or already confirmed. For example, in the InviteFrdSession, BG only selects users who have no existing “friend” or “pending” relationship with the requester to receive a new friend request.