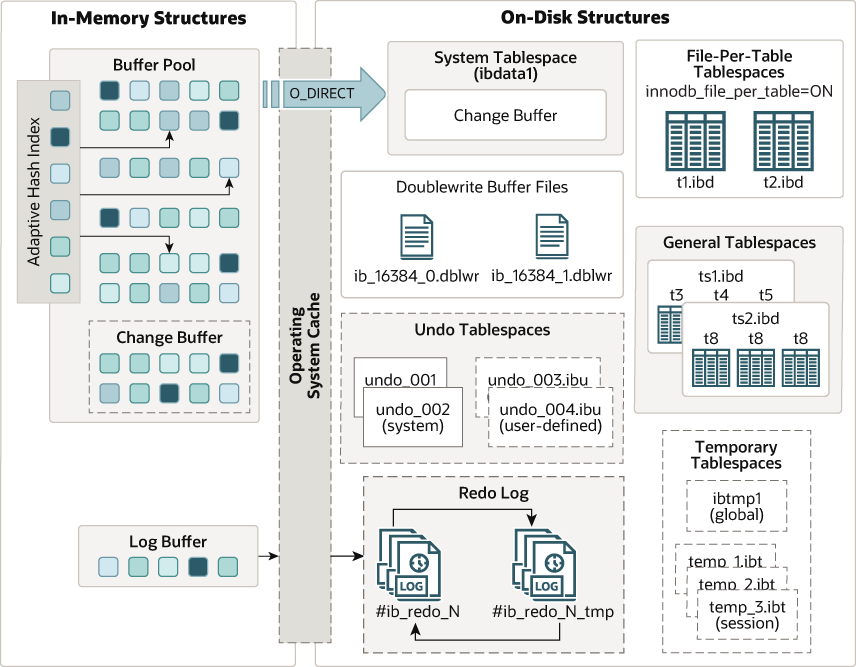
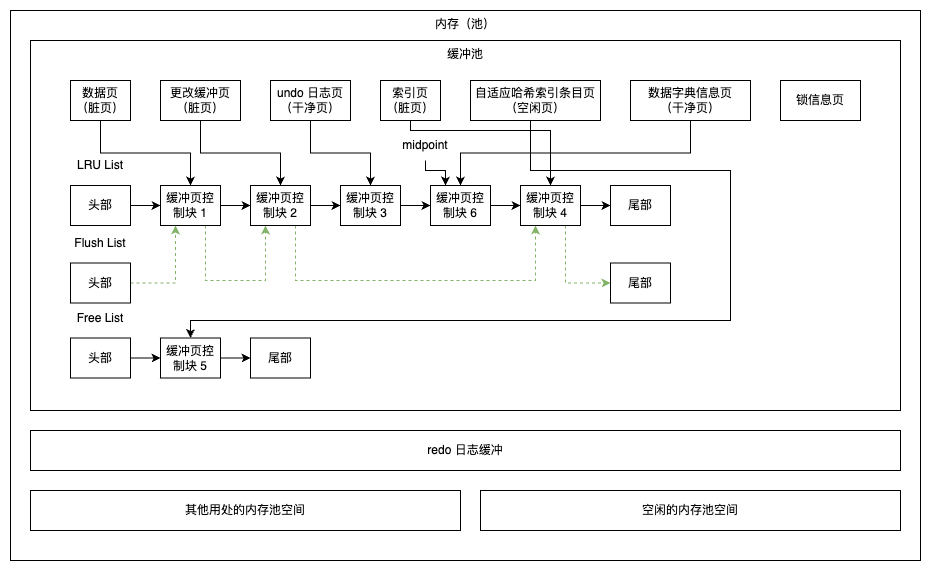
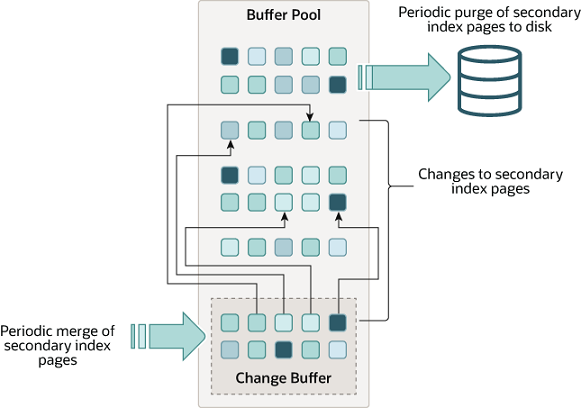
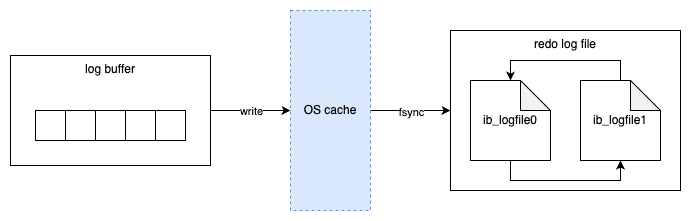
Data Model
SQL++ has a more flexible data model:
- It relaxes traditional SQL’s strict rules to handle modern, semi-structured data like JSON or CBOR.
- SQL++ databases can store self-describing data, meaning you don’t need a predefined schema (data structure).
Supports diverse data types:
- Data can be single values (scalars), tuples (a set of key-value pairs), collections (like arrays or multisets), or combinations of these.
- Unlike traditional SQL, tuples in SQL++ are unordered, which means the order of attributes doesn’t matter.
Allows duplicate attribute names but discourages them:
- This is to accommodate non-strict formats like JSON.
- However, duplicate names can lead to unpredictable query results, so they’re not recommended.
Two kinds of missing values: NULL and MISSING:
NULL: Means an attribute exists but has no value.MISSING: Means the attribute doesn’t exist at all.- This distinction is useful for clearer query results and error handling.
Importance of MISSING:
- SQL++ doesn’t stop processing if some data is missing; instead, it marks those cases as
MISSINGand continues. - This makes queries more robust and tolerant of data inconsistencies.
Accessing Nested Data
SQL-92 vs. Modern Data:
- SQL-92 only supports tables with rows (tuples) containing simple values (scalars).
- Modern data formats often include nested structures, where attributes can hold complex data types like arrays, tables, or even arrays of arrays.
Nested Data Example:


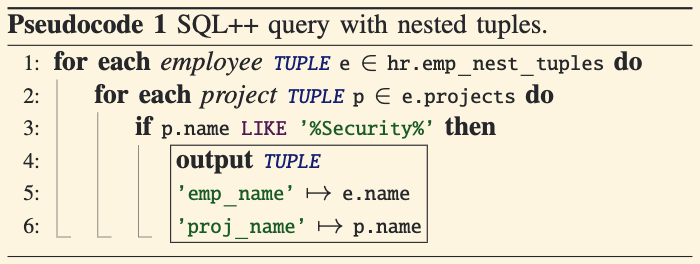
- In the example, the
projectsattribute of an employee is an array of tuples, representing multiple projects each employee is involved in.
Querying Nested Data in SQL++:
- SQL++ can handle such nested data without adding new syntax to SQL.
- For example, a query can find employees working on projects with “security” in their names and output both the employee’s name and the project’s name.
How It Works:
- SQL++ uses left-correlation, allowing expressions in the
FROMclause to refer to variables declared earlier in the same clause. - For instance,
e.projectsaccesses the projects of an employeee. - This relaxes SQL’s restrictions and effectively enables a join between an employee and their projects.
Using Variables in Queries:
- SQL++ requires explicit use of variables (e.g.,
e.nameinstead of justname) because schema is optional and cannot guarantee automatic disambiguation. - If a schema exists, SQL++ can still optimize by rewriting the query for clarity and execution.
Flexibility with Nested Collections:
- Variables in SQL++ can represent any type of data—whether it’s a table, array, or scalar.
- These variables can be used seamlessly in
FROM,WHERE, andSELECTclauses.
Aliases Can Bind to Any Data Type:
- In SQL++, variables (aliases) don’t have to refer only to tuples.
- They can bind to arrays of scalars, arrays of arrays, or any combination of scalars, tuples, and arrays.
Flexibility in Querying Nested Data:
- Users don’t need to learn new query syntax for different data structures.
- The same unnesting feature is used regardless of whether the data is an array of tuples or an array of scalars.
Example:



- If the
projectsattribute is an array of strings (instead of tuples), SQL++ queries can still process it. - The query would range over
e.projectsand bindpto each project name (a string).
Relaxed Semantics Compared to SQL:
- In traditional SQL, the
FROMclause binds variables strictly to tuples. - SQL++ generalizes this by treating the
FROMclause as a function that can bind variables to any type of data—not just tuples.
Practical Outcome:
- In the example, the
FROMclause produced variable bindings like{e: employee_data, p: project_name}. - This allows the query to handle data structures that SQL would not support without extensions.
ABSENCE OF SCHEMA AND SEMI-STRUCTURED DATA
Schemaless Data:
- Many modern data formats (e.g., JSON) don’t require a predefined schema to describe their structure.
- This allows for flexible and diverse data, but it also introduces heterogeneity.
Types of Heterogeneity:
- Attribute presence: Some tuples may have a specific attribute (e.g.,
x), while others may not. - Attribute type: The same attribute can have different types across tuples. For example:
- In one tuple,
xmight be a string. - In another tuple,
xmight be an array.
- In one tuple,
- Element types in collections: A collection (e.g., an array or a bag) can have elements of different types. For example:
- The first element could be a string, the second an integer, and the third an array.
- Legacy or data evolution: These heterogeneities often result from evolving requirements or data conversions (e.g., converting XML to JSON).
Heterogeneity Is Not Limited to Schemaless Data:
- Even structured databases can have heterogeneity. For example:
- Hive’s union type allows an attribute to hold multiple types, like a string or an array of strings.
How SQL++ Handles It:
- SQL++ is designed to work seamlessly with heterogeneous data, whether the data comes from a schemaless format or a schema-based system.
- It offers features and mechanisms to process such data flexibly, without enforcing rigid structure requirements.
Missing Attributes
Representation of Missing Information:
In SQL, a missing value is typically represented as
NULL(e.g., Bob Smith’s title in the first example).In SQL++, there’s an additional option: simply omitting the attribute altogether (as seen in the second example for Bob Smith).
NULLvs.MISSING:NULL: Indicates the attribute exists but has no value.MISSING: Indicates the attribute is entirely absent.SQL++ supports distinguishing between these two cases, unlike traditional SQL.
Why This Matters:
Some data systems or formats (e.g., JSON) naturally omit missing attributes rather than assigning a
NULLvalue.SQL++ makes it easy to work with both approaches by allowing queries to handle
NULLandMISSINGvalues distinctly.
Query Behavior:
Queries in SQL++ can propagate
NULLandMISSINGvalues as they are.The system introduces the special value
MISSINGto represent absent attributes, allowing clear differentiation fromNULL.
MISSING as a Value
What Happens When Data is Missing:
- If a query references an attribute that doesn’t exist in a tuple (e.g.,
e.titlefor Bob Smith), SQL++ assigns the valueMISSING. - This avoids query failures and ensures processing can continue.
Three Cases Where MISSING is Produced:
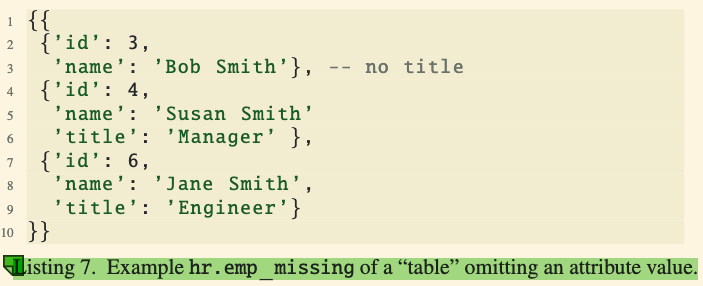
- Case 1: Accessing a missing attribute. For example,
{id: 3, name: 'Bob Smith'}.titleresults inMISSING. - Case 2: Using invalid input types for functions or operators (e.g.,
2 * 'some string'). - Case 3: When
MISSINGis an input to a function or operator, it propagates asMISSINGin the output.
SQL Compatibility Mode:
- In SQL compatibility mode,
MISSINGbehaves likeNULLfor compatibility. For instance,COALESCE(MISSING, 2)will return2, just asCOALESCE(NULL, 2)does in SQL.
Propagation of MISSING in Queries:
- In queries,
MISSINGvalues flow naturally through transformations, enabling consistent handling of absent data. - For example, in a
CASEstatement, ife.titleevaluates toMISSING, the result of the entireCASEexpression will also beMISSING.
Results with MISSING:
- If a query result includes
MISSING, SQL++ will omit the attribute from the result tuple. - In communication with external systems like JDBC/ODBC,
MISSINGis transmitted asNULLto ensure compatibility.
RESULT CONSTRUCTION,NESTING, AND GROUPING
Creating Collections of Any Value
Power of SELECT VALUE:
- The
SELECT VALUEclause in SQL++ allows constructing collections of any type of data, not just tuples. - It enables creating outputs that match the structure of nested data without flattening it unnecessarily.
Example Query:

- The query in Listing 10 demonstrates how to use
SELECT VALUEto extract only the “security” projects of employees, resulting in a nested structure. - Each employee’s tuple includes their ID, name, title, and a collection of their security-related projects.
Result:

- Listing 11 shows the result where each employee has a field
security_projcontaining a nested collection of projects that match the condition (e.g., projects with “Security” in the name).
Key Difference from Standard SQL:
- SQL’s
SELECTclause can be viewed as shorthand forSELECT VALUE, but with differences:- SQL automatically coerces subquery results into scalar values, collections of scalars, or tuples based on context.
- In contrast,
SELECT VALUEin SQL++ consistently produces a collection and does not apply implicit coercion.
Flexibility:
- SQL++ avoids implicit “magic” by explicitly treating
SELECTas shorthand forSELECT VALUE. - This approach aligns more closely with functional programming principles, making it easier to handle and compose nested data results.
GROUP BY and GROUP AS
Introduction to GROUP BY ... GROUP AS:
- This feature extends SQL’s
GROUP BYfunctionality, allowing groups (and their contents) to be directly accessible in theSELECTandHAVINGclauses. - It is more efficient and intuitive for creating nested results compared to traditional SQL, especially when the output nesting doesn’t directly align with the input data structure.
How It Works:
- Generalization: Unlike SQL, which limits access to grouped data in
GROUP BY, SQL++ allows accessing the full group details as part of the query. - Pipeline Model: SQL++ processes queries in a step-by-step fashion, starting with
FROM, followed by optional clauses likeWHERE,GROUP BY,HAVING, and ending withSELECT.
Example:
- In the query from Listing 12, employees are grouped by their project names (converted to lowercase), and a nested list of employees for each project is created.
- The
GROUP BY LOWER(p) AS p GROUP AS gclause groups data and stores each group ing. - The
SELECTclause then extracts project names and employees.
Result:
- The output (shown in Listing 13) contains nested objects:
- Each object has a
proj_name(e.g.,'OLTP Security') and anemployeesfield listing the names of employees associated with that project.
- Each object has a
Details of GROUP BY ... GROUP AS:
- The clause produces bindings like the ones in Listing 14, where each group (
g) includes all the data for its corresponding key (p). - The result allows users to flexibly access and format the grouped data.
SQL++ Flexibility:
- SQL++ allows placing the
SELECTclause either at the start or the end of a query block, enhancing readability and flexibility. - This approach is more consistent with functional programming and reduces constraints found in traditional SQL.
Advanced Features:
- SQL++ supports additional analytical tools like
CUBE,ROLLUP, andGROUPING SETS, making it highly compatible with SQL but better suited for nested and semi-structured data.
Aggregate Functions
Limitations of Traditional SQL Aggregate Functions:
- Aggregate functions like
AVGandMAXin traditional SQL lack composability. - They work directly on table columns but don’t easily integrate with more complex expressions or subqueries.
SQL++ Solution:
- SQL++ introduces composable aggregate functions, such as
COLL_AVG(for calculating the average of a collection) andCOLL_MAX. - These functions take a collection as input and return the aggregated value.
Importance of Composability:
- In SQL++, data is conceptually materialized into a collection first, then passed to the composable aggregate function.
- While this materialization is conceptual, SQL++ engines optimize the execution (e.g., using pipelined aggregation).
Example 1: Calculating the Average Salary of Engineers:

- SQL Query (Listing 15): Uses
AVG(e.salary)directly. - SQL++ Core Query (Listing 16): Converts
e.salaryinto a collection and applies theCOLL_AVGfunction. - SQL++ clearly defines the flow of data, making it more intuitive and flexible.
Example 2: Calculating the Average Salary of Engineers by Department:

- SQL Query (Listing 17): Uses
GROUP BYandAVG. - SQL++ Core Query (Listing 18):
- Uses
GROUP BY ... GROUP ASto form groups. - Feeds each group into
COLL_AVGto calculate the average salary. - Constructs the result using the
SELECT VALUEclause, explicitly specifying the output format.
- Uses
Flexibility of SQL++ Style:
- SQL++ allows the
SELECTclause to be written at the end of a query block, consistent with functional programming styles. - This enhances readability and composability while maintaining compatibility with SQL.
Pivoting and Unpivoting
UNPIVOT: Transforming Attributes into Rows
What is Unpivoting?
Unpivoting is the process of converting attribute names (used as keys) into data rows.
This is useful for cases where key-value pairs in the data need to be analyzed as individual rows.
Example (Listing 19-21):

Input: A
closing_pricescollection where stock symbols (amzn,goog,fb) are attributes with prices as values.Query (Listing 20): The
UNPIVOTclause transforms these attributes into rows with fields forsymbolandprice.Output (Listing 21): A flattened structure where each row contains the date, stock symbol, and price.
Pivoting
- Purpose of Pivoting:
- Pivoting transforms rows into attributes (columns).
- Example from Listings 23-25:

- Input (Listing 23): Rows of
today_stock_priceswhere each stock symbol and its price are separate rows. - Query (Listing 24): The
PIVOToperation turns these rows into a single object, usingsp.symbolas attribute names andsp.priceas their values. - Output (Listing 25): A tuple where each stock symbol (
amzn,goog,fb) is an attribute, and their corresponding prices are the values.
Combining Grouping and Pivoting
- Using Pivot with Grouping:
- Combining
GROUP BYandPIVOTenables aggregation of grouped rows into a more structured output. - This is particularly useful when working with time-series data or hierarchical datasets.
- Combining
- Example Query (Listing 26):
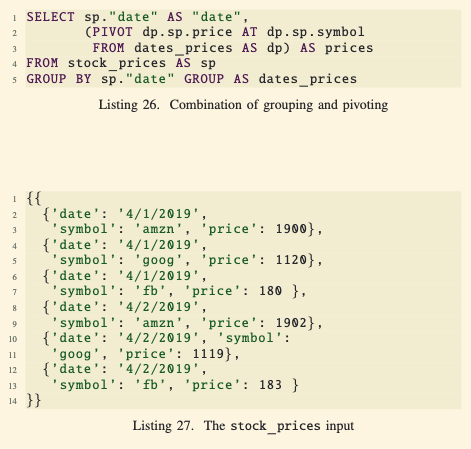

- Input: Data from
stock_prices(Listing 27), which includes stock prices for multiple dates as individual rows. - Query:
- Groups the data by
dateusingGROUP BY sp.date. - Pivots the grouped rows to produce a nested structure where each date contains all its stock prices as attributes.
- Groups the data by
- Output (Listing 28): For each date, an object with a
pricesfield lists the stock symbols as attributes and their respective prices as values.
Questions
SQL++ identifies aggregate functions as an SQL violation of functional composability. Give an example of an aggregate function and describe how it violates SQL’s functional composability.
Aggregate Function:
COLL_AVG()Violation Explanation:
In traditional SQL, aggregate functions like
AVGprocesses the column and returns a single value.In SQL++, this issue is resolved by providing composable versions of aggregate functions, such as
COLL_AVG, which operate on collections, allowing intermediate results to flow naturally into the aggregation.
With SQL++, what is the difference between NULL and Missing?
NULL: Indicates that an attribute exists but has no value.
MISSING: Indicates that an attribute is completely absent in the data.
True or false: One must define a schema for data prior to using SQL++.
False:
- SQL++ supports schema-optional and schema-less data formats, such as JSON.
- While schemas can improve query optimization and validation, SQL++ can process data without requiring predefined schemas, making it highly flexible for semi-structured data use cases.
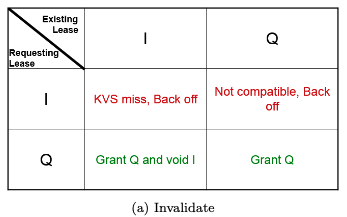
How does the I lease prevent a thundering herd?
The I lease (Inhibit Lease) prevents a thundering herd problem by ensuring that only one read session at a time is allowed to query the RDBMS for a missing key-value pair in the Key-Value Store (KVS). Here’s how it works:
Thundering Herd Problem:
When a key-value pair is not found in the KVS (a KVS miss), multiple read sessions might simultaneously query the RDBMS to fetch the value.
This can overload the RDBMS and degrade performance under high concurrency.
Role of the I Lease:
When the first read session encounters a KVS miss, it requests an I lease for the key.
Once the I lease is granted, the KVS prevents other read sessions from querying the RDBMS for the same key.
All other read sessions must “back off” and wait for the value to be updated in the KVS by the session holding the I lease.
Result:
The session with the I lease queries the RDBMS, retrieves the value, and populates the KVS.
Subsequent read sessions observe a KVS hit and do not need to access the RDBMS.
This mechanism avoids simultaneous RDBMS queries, effectively solving the thundering herd problem.
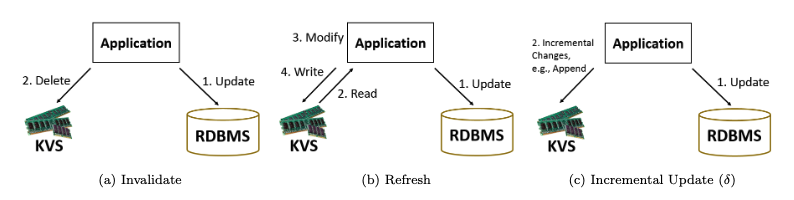
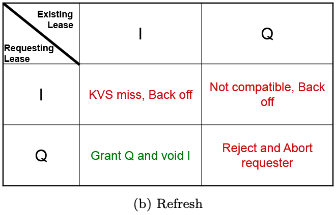
What is the difference between invalidate and refresh/refill for maintaining the cache consistent with the database management system?
- Invalidate: Deletes stale cache entries to prevent incorrect reads, but at the cost of forcing subsequent queries to access the RDBMS.
- Refresh/Refill: Proactively updates the cache with new data, ensuring consistent reads while reducing future load on the RDBMS at the expense of immediate computation.
Describe how CAMP inserts a key-value pair in the cache.
Check Cache Capacity
- If there is enough memory to store the new key-value pair:
- The pair is inserted directly into the appropriate priority group based on its cost-to-size ratio.
- L is not updated.
- If the cache is full:
- CAMP selects one or more key-value pairs to evict based on their H(p) values.
- It removes the pair(s) with the lowest H(p) values until there is sufficient space for the new pair.
Insert the New Pair
- The new key-value pair p is added to the cache, and its H(p) value is computed and recorded.
- The pair is placed in the appropriate priority queue based on its cost-to-size ratio.
How does BG compute the SoAR of a database management system?
- Define the SLA.
- Run a series of experiments with increasing numbers of threads (T) to find the peak throughput while ensuring SLA compliance.
Reference: https://escholarship.org/content/qt2bj3m590/qt2bj3m590_noSplash_084218340bb4e928c05878f04d01f04d.pdf