选择合适的 CPU
一般而言,当前数据库的应用类型可分为两大类:OLTP(Online Transaction Processing,在线事务处理)和 OLAP(Online Analytical Processing,在线分析处理)。这是两种截然不同的数据库应用。OLAP 多用于数据仓库或数据集中,一般需要执行复杂的 SQL 语句来进行查询;OLTP 多用于日常的事务性应用中,如银行交易、在线商品交易、Blog、网络游戏等应用。相对于 OLAP,OLTP 应用中的数据库容量较小。
InnoDB 存储引擎一般都应用于 OLTP 的数据库应用,这种应用的特点如下:
- 用户操作的并发量大;
- 事务处理的时间一般比较短;
- 查询的语句较为简单,一般走索引;
- 复杂的查询较少。
可以看出,OLTP 的数据库应用本身对 CPU 的要求并不是很高,因为复杂的查询(如排序、连接等)非常耗费 CPU,而这些操作在 OLTP 应用中较少发生。因此,可以说:OLAP 是 CPU 密集型的操作,OLTP 是 I/O 密集型的操作。建议在采购服务器时,将更多注意力放在 I/O 性能的配置上。
OLTP 为主:优先关注存储子系统性能,CPU 核数 4–8 核即可满足大多数场景,多核有助于并发连接处理;单语句并行受限于 MySQL 内核,需依赖多会话并发提升吞吐。
OLAP 为主:建议选用多核高主频机器,如 16–32 核以上,同时配合支持并行查询的引擎(Aurora/MySQL HeatWave)以充分发挥 CPU 性能。
为了支持多核应用,我们可以考虑 InnoDB 并行特性与调优:
并行 I/O 线程
innodb_read_io_threads与innodb_write_io_threads默认均为 4,或为可用逻辑处理器数的一半,且最小为 4;可手动增至与 CPU 核数相同,提升 I/O 吞吐。合理设置范围为 1–64,具体值需结合存储性能与并发需求测试。
并行索引扫描
MySQL 8.0.14 起支持 innodb_parallel_read_threads,可并行扫描聚簇索引子树,加速诸如 CHECK TABLE、COUNT(*) 等操作。默认值为可用 CPU 数,或根据系统特性自动调整;在多核机上带来显著读取性能提升。
并行 DDL 构建
从 MySQL 8.0.27 起,innodb_ddl_threads 使在线创建二级索引时可并发执行多线程,显著缩短大表的 DDL 时间。
内存的重要性
InnoDB 将数据和索引缓存在一个很大的缓冲池中,即 InnoDB Buffer Pool。因此,内存的大小直接影响了数据库的性能。
Percona 公司的 CTO Vadim 对此做了一次测试,以此反映内存的重要性:数据和索引总大小为 18 GB,然后将缓冲池的大小分别设为 2 GB、4 GB、6 GB、8 GB、10 GB、12 GB、14 GB、16 GB、18 GB、20 GB、22 GB,再进行 sysbench 的测试。可以发现,随着缓冲池的增大,测试结果 TPS(Transactions Per Second)会线性增长。当缓冲池增大到 20 GB 和 22 GB 时,数据库的性能有了极大的提高,因为此时缓冲池的大小已经大于数据文件本身的大小,所有对数据文件的操作都可以在内存中进行。因此,这时的性能应该是最优的,再增大缓冲池并不能再提高数据库的性能。
所以,应该在开发应用前预估活跃数据库的大小是多少,并以此确定数据库服务器内存的大小。当然,要使用更多的内存还必须使用 64 位的操作系统。
如何判断当前数据库的内存是否已经达到瓶颈了呢?可以通过查看当前服务器的状态,比较物理磁盘的读取和内存读取的比例来判断缓冲池的命中率,通常 InnoDB 存储引擎的缓冲池命中率不应该小于 99%,如:
1 | mysql> SHOW GLOBAL STATUS LIKE 'innodb%read%'\G |
上述参数的具体含义如下表所示:
| 参数 | 说明 |
|---|---|
| Innodb_buffer_pool_reads | 表示从物理磁盘读取页的次数 |
| Innodb_buffer_pool_read_ahead | 预读的次数 |
| Innodb_buffer_pool_read_ahead_evicted | 预读的页,但是没有被读取就从缓冲池中被替换的页的数量,一般用来判断预读的效率 |
| Innodb_buffer_pool_read_requests | 从缓冲池中读取页的次数 |
| Innodb_data_read | 总共读入的字节数 |
| Innodb_data_reads | 发起读请求的次数,每次读取可能需要读取多个页 |
以下公式可以计算各种对缓冲池的操作:
$$\text{缓冲池命中率} =
\frac{\text{Innodb_buffer_pool_read_requests}}
{\text{Innodb_buffer_pool_read_requests} + \text{Innodb_buffer_pool_read_ahead} + \text{Innodb_buffer_pool_reads}}$$
$$\text{平均每次读取的字节数} =
\frac{\text{Innodb_data_read}}{\text{Innodb_data_reads}}$$
从上面的例子看,缓冲池命中率 = 167 051 313 / (167 051 313 + 129 236 + 0) ≈ 99.92%。
即使缓冲池的大小已经大于数据库文件的大小,这也并不意味着没有磁盘操作。数据库的缓冲池只是一个用来存放热点的区域,后台的线程还负责将脏页异步地写入到磁盘。此外,每次事务提交时还需要将日志写入重做日志文件。
硬盘的选择
传统机械硬盘(HDD)
在现代数据库系统中,存储子系统的性能直接影响到应用的响应速度和吞吐能力。传统机械硬盘依赖旋转盘片和寻道臂,虽然成熟稳定,却在随机访问场景中存在较高的延迟;固态硬盘以闪存为存储介质,通过消除机械部件带来了数百倍的随机 I/O 性能提升;而 NVMe 接口的固态硬盘则更进一步,通过 PCIe 通道实现更低的延迟和更高的并发吞吐。针对这些不同类型的硬盘,MySQL 提供了多项优化参数和社区方案,以充分利用闪存特性并扩展内存缓冲池,从而在 OLTP 和 OLAP 场景中都能获得优异的数据库性能。
传统机械硬盘的主要性能指标包括寻道时间和转速。寻道时间指从发出读写指令到磁头到达目标扇区所需的时间,目前高端 SAS 硬盘的平均寻道时间约为三毫秒;转速以每分钟转数(RPM)计量,常见值为 7200RPM 和 15000RPM。由于机械硬盘在数据访问时需要进行磁头定位和盘片旋转,随机 I/O 操作的响应时间通常在数毫秒级别,而顺序读写则能达到上百兆字节每秒的吞吐。为提高性能和可靠性,生产环境中常将多块机械硬盘通过 RAID 0 或 RAID 10 组合,以提升顺序吞吐和分散热点。
固态硬盘
固态硬盘,也称基于闪存的固态硬盘,是近年来出现的一种新型存储设备,它内部由闪存颗粒(Flash Memory)组成,具有低延迟、低功耗和抗震性等优点。传统机械硬盘依赖磁头寻道和旋转延迟,固态硬盘无需机械移动部件,因而能提供一致的随机访问时间,一般小于0.1毫秒。闪存中的数据不可直接覆盖写入,只能通过扇区(sector)或块级的擦除(erase)操作来重写,在擦除前需要先对整个擦除块进行擦除,该擦除块大小通常是128KB或256KB,并且每个擦除块有写入次数的寿命限制,需要配合垃圾回收和磨损均衡算法来解决写入次数限制问题。固态硬盘的控制器会将主机的逻辑地址映射成实际的物理地址,写操作同时需要更新映射表,带来额外的开销,但相对于机械硬盘的寻道和旋转延迟,这些开销仍然较低。
在数据库领域,尤其是 MySQL 的 InnoDB 存储引擎中,充分利用固态硬盘所带来的高 IOPS 特性是提升性能的重要手段之一。在 InnoDB 中,可以通过调整 innodb_io_capacity 和 innodb_io_capacity_max 参数来控制后台 I/O 的并发数和速率,使得刷新操作更加均匀且高效,对于 SSD 存储,一般建议将这两个参数设置为几万甚至更高的值,以充分发挥闪存的并行读写能力。除此之外,还可以使用 InnoDB 8.0 系列中提供的 L2 Cache 解决方案,将 SSD 作为二级缓存层,以进一步扩充内存缓冲池的容量,从而降低对主存的依赖并提升数据库整体吞吐量。Facebook 推出的 Flash Cache 和 Percona 的 Flashcache 等方案也能在操作系统层面提供类似功能,但 InnoDB 原生的 L2 Cache 与存储引擎深度集成,能够获得更好的效果。
优化 InnoDB 磁盘 I/O 还可以从以下几个方面入手:首先,将 innodb_buffer_pool_size 设置为系统内存的 50% 到 75%,这样大部分热数据可以缓存在内存中,减少对磁盘的访问需求。其次,将 innodb_flush_method 设置为 O_DIRECT,避免文件系统缓存与 InnoDB 缓冲池之间的双重缓存带来的不必要 I/O 开销。再者,根据操作系统和硬件特性,选择合适的 I/O 调度器,例如在 Linux 上使用 noop 或 deadline 调度器,以减少调度延迟并配合 SSD 的并行特性。另外,当系统物理内存充足时,应尽量避免使用交换空间,因为即使是 SSD,频繁的交换也会缩短其寿命并带来不必要的写放大效应。
操作系统的选择
操作系统的选择和调优对数据库的响应速度、并发处理能力以及 I/O 性能具有至关重要的影响。合适的 OS 及其配置不仅能够发挥底层硬件的最大性能,还能减少不必要的系统开销,从而提升 MySQL 的整体吞吐量与稳定性。
Linux vs. Windows vs. BSD
- Linux:MySQL 在 Linux/Unix 平台上经过了长期优化,社区与厂商(包括 Oracle)主要以 Linux 为开发和测试环境,因此在性能和兼容性方面通常优于 Windows。Linux 的轻量内核和丰富的工具链也有助于更精细的调优和故障排查。
- Windows:尽管 MySQL 支持 Windows,但在高并发、大规模生产环境下,不如 Linux 稳定,且 Windows Server 的授权费用和系统开销较高。
- BSD/macOS:较少用于生产环境,社区支持与文档相对有限,调优经验不如 Linux 丰富。
Linux 发行版与版本选择
发行版推荐
- RHEL 及衍生版(CentOS、Rocky Linux、Oracle Linux):长期支持(LTS)版本稳定,企业级特性丰富,文档与社区调优经验充足。
- Debian/Ubuntu Server:包管理灵活,社区活跃,适合快速迭代与测试环境;Ubuntu LTS 版本也可用于生产,但需注意内核参数差异。
- 其他(SUSE、Arch 等):在特定场景下可用,但社区调优资料相对较少。
内核版本的话,优先选择稳定的 LTS 内核(如 5.x 系列),以获得长期安全和性能更新;可根据硬件特性(如最新 NVMe SSD)适当测试更高版本内核的性能优势。
文件系统的选择
不同文件系统在并发 I/O 性能、数据完整性保障、快照支持和对闪存设备的优化上各有侧重。一般而言,若以大文件吞吐和并发写入为主,可优先考虑 XFS;若追求成熟稳定和通用场景,可选用 ext4;若需要原生快照、子卷和校验功能,可考虑 Btrfs;若对数据完整性和自我修复有极致需求,可采用 ZFS;若存储介质为 NAND 闪存且写放大需严格控制,则 F2FS 是最佳方案。
在需要处理海量大文件或日志聚合的场景下,XFS 拥有优异的并发写入性能和在线扩展能力,能够在多线程写入时保持稳定吞吐。
对于大量小文件的创建、删除和元数据访问,ext4 表现更加均衡,元数据操作延迟较低,且社区支持度极高。
Btrfs 和 ZFS 均内置数据与元数据校验和机制,可以在读写时检测并自动修复错误,显著提高数据完整性保障。
ZFS 采用 Copy-On-Write 事务模型,所有写入先在新块上完成,元数据与数据层层校验后再引用,有助于避免因崩溃导致的不一致状态。
Btrfs 原生支持轻量级子卷与快照,通过写时复制技术,创建快照几乎零成本,便于在线备份和回滚。
ZFS 快照同样高效,一旦创建可立即生效且节省空间,并可通过 zfs send/recv 在集群或异地环境中可靠地迁移数据集。
Btrfs 支持透明在线压缩,既能节省存储空间,也能降低 SSD 写入量;ZFS 则提供多种压缩算法(如 LZ4),可根据性能与压缩率需求灵活选择。
F2FS 是针对 NAND 闪存设计的日志结构文件系统,通过减少写放大和高效的清理机制,提高中低端 SSD 和 eMMC 的使用寿命与性能。
RAID 的设置
RAID(Redundant Array of Independent Disks,独立磁盘冗余阵列)的基本思想就是把多个相对便宜的硬盘组合起来,成为一个磁盘数组,使性能达到甚至超过一个价格昂贵、容量巨大的硬盘。由于将多个硬盘组合成一个逻辑扇区,RAID 看起来就像一个单独的硬盘或逻辑存储单元,因此操作系统只会把它当作一个硬盘。
RAID 的作用是:
- 增强数据集成度;
- 增强容错功能;
- 增加处理量或容量。
根据不同磁盘的组合方式,常见的 RAID 组合方式可分为 RAID 0、RAID 1、RAID 5、RAID 10 和 RAID 50 等。
RAID 0:将多个磁盘合并成一个大的磁盘,不会有冗余,并行 I/O,速度最快。RAID 0 亦称为带区集(Striping),它将多个磁盘并列起来,使之成为一个大磁盘,如下图所示。
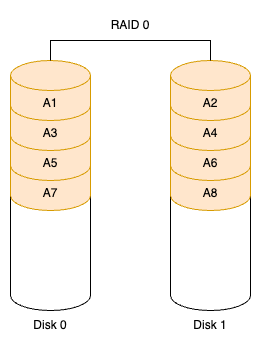
在存放数据时,会将数据按磁盘的个数进行分段,同时将这些分段并行写入各个磁盘。所以,在所有的 RAID 级别中,RAID 0 的速度是最快的。但是 RAID 0 没有冗余功能,如果一个磁盘(物理)损坏,则所有的数据都会丢失。
理论上,多磁盘的效能等于(单一磁盘效能)×(磁盘数),但实际会受总线 I/O 瓶颈及其他因素的影响,RAID 效能会随边际递减。也就是说,假设一个磁盘的效能是 50 MB/s,两个磁盘的 RAID 0 效能约为 96 MB/s,三个磁盘的 RAID 0 也许是 130 MB/s 而不是理论值 150 MB/s。
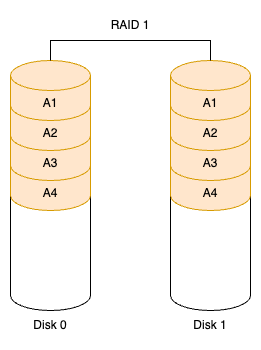
RAID 1:两组以上的 N 个磁盘相互作为镜像(如下图所示)。在一些多线程操作系统中,RAID 1 能有很好的读取速度,但写入速度略有降低。除非主磁盘和镜像磁盘同时损坏,否则只要有一块磁盘正常就能维持运行,可靠性最高。RAID 1 就是镜像,其原理是在主硬盘上存放数据的同时,也在镜像硬盘上写入相同的数据。当主硬盘(物理)损坏时,镜像硬盘就顶替其工作。由于有镜像磁盘做数据备份,RAID 1 的数据安全性在所有 RAID 级别中最高。但是,无论用多少块磁盘作为 RAID 1,仅有一块磁盘有效,是所有 RAID 级别中磁盘利用率最低的一个级别。
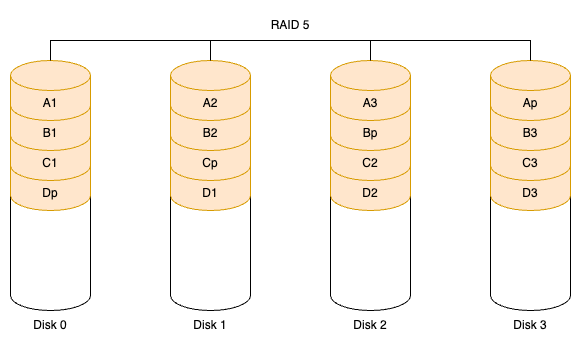
RAID 5:是一种兼顾存储性能、数据安全和存储成本的存储解决方案。它使用 Disk Striping(硬盘分区)技术,至少需要三块硬盘。RAID 5 不对存储的数据进行完整备份,而是将数据和对应的奇偶校验信息存储到 RAID 5 的各个磁盘上,且奇偶校验信息和对应的数据分别存储在不同的磁盘上。当 RAID 5 中的一块磁盘发生故障后,可利用其余磁盘上的数据和奇偶校验信息,恢复丢失的数据。RAID 5 可视为 RAID 0 和 RAID 1 的折中方案,为系统提供数据安全保障,但其安全性低于镜像,磁盘空间利用率高于镜像。RAID 5 具有与 RAID 0 相近的读取速度,只是多了一条奇偶校验信息;写入速度相对较慢,若使用 Write Back 可有所改善。同时,由于多个数据块共用一条奇偶校验信息,RAID 5 的磁盘空间利用率高于 RAID 1,存储成本相对较低。RAID 5 的结构如下图所示。
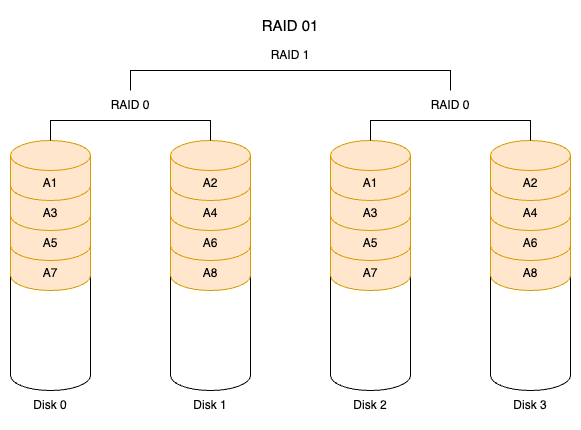
RAID 10 是先镜像再分区数据,将所有硬盘分为两组,视为 RAID 0 的最低组合,然后将这两组各自视为 RAID 1 运行。RAID 10 有着不错的读取速度,而且拥有比 RAID 0 更高的数据保护性。RAID 01 则与 RAID 10 程序相反,先以 RAID 0 将数据划分到两组硬盘,RAID 1 将所有的硬盘分为两组,变成 RAID 1 的最低组合,而将两组硬盘各自视为 RAID 0 运行。RAID 01 比 RAID 10 有着更快的读写速度,不过也多了一些会让整个硬盘组停止运转的几率,因为只要同一组的硬盘全部损毁,RAID 01 就会停止运作,而 RAID 10 可以在牺牲 RAID 0 的优势下正常运作。RAID 10 巧妙地利用了 RAID 0 的速度及 RAID 1 的安全(保护)两种特性,它的缺点是需要较多的硬盘,因为至少必须拥有四个以上的偶数硬盘才能使用。RAID 10 和 RAID 01 的结构如下图所示。
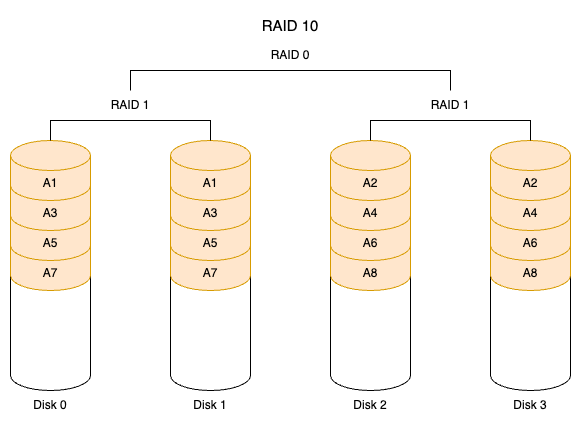
假设有 4 块磁盘 D0、D1、D2、D3:
- RAID 01
- 条带组 A:D0、D1 做 RAID 0
- 镜像组 B:D2、D3 做 RAID 0,然后镜像 A←→B
一旦 D0、D1 同时损坏,A 组失效,整个逻辑盘挂掉——尽管 D2、D3 还健康,但无法自动接管。
- RAID 10
- 镜像对 1:D0⇄D1 做 RAID 1
- 镜像对 2:D2⇄D3 做 RAID 1
- 条带化:将数据交替写到 “对 1” 和 “对 2”
即便 D0、D2 同时故障,只要 D1、D3 健康,每个条带仍有一个副本存活,整个卷继续可用。
条带的实现原理如下:系统首先将待存储的数据按预定义的条带大小(如 64 KB、128 KB)切分为若干数据块,每个数据块称为一个“条带”。分割后的条带按照轮询(round-robin)方式依次写入多块磁盘或 SSD。比如,第一条带写入设备 A,第二条带写入设备 B,第三条带再回到设备 A,依此循环。
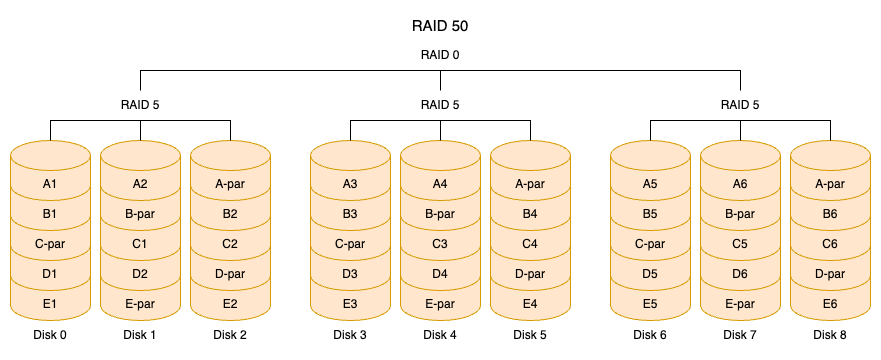
RAID 50:RAID 50 也被称为镜像阵列条带,由至少六块硬盘组成,像 RAID 0 一样,数据被分区成条带,在同一时间内向多块磁盘写入;像 RAID 5 一样,也是以数据和校验位来保证数据的安全,且校验条带均匀分布在各个磁盘上,其目的是提高 RAID 5 的读写性能。
对于数据库应用来说,RAID 10 是最好的选择,它同时兼顾了 RAID 1 和 RAID 0 的特性。但是,当一个磁盘失效时,性能可能会受到很大的影响,因为条带会成为瓶颈。也就是说,当 RAID 10 中的某块磁盘发生故障时,阵列不会像 RAID 0 那样整体挂掉,但其条带并行度会立刻下降,进而造成 I/O 吞吐能力的衰减。具体来说,RAID 10 在正常状态下,将数据在多对镜像组之间条带化写入,可并行利用所有镜像对的读写能力;而一旦某个镜像对失去一块盘,整个镜像对的条带操作只能依赖剩余的单盘,导致该镜像对“窄化”,从而拖慢整组的并行访问速度。
RAID Write Back 功能
RAID Write Back 功能是指 RAID 控制器能够将写入的数据放入自身的缓存中,并把它们安排到后面再执行。这样做的好处是,不用等待物理磁盘实际写入的完成,因此写入变得更快了。对于数据库来说,这显得十分重要。例如,对重做日志的写入,在将 sync_binlog 设置为 1 的情况下二进制日志的写入、脏页的刷新等都可以使得性能得到明显的提升。
但是,当操作系统或数据库关机时,Write Back 功能可能会破坏数据库的数据。这是由于已经写入的数据可能还在 RAID 卡的缓存中,数据可能并没有完全写入磁盘,而这时故障发生了。为了解决这个问题,目前大部分的硬件 RAID 卡都提供了电池备份单元 (BBU, Battery Backup Unit),因此可以放心地开启 Write Back 的功能。不过我发现每台服务器的出厂设置都不相同,应该将 RAID 设置要求告知服务器提供商,开启一些认为需要的参数。
如果没有启用 Write Back 功能,那么在 RAID 卡设置中显示的就是 Write Through。Write Through 没有缓存写入,因此写入性能可能不是很好,但它却是最安全的写入。
即使用户开启了 Write Back 功能,RAID 卡也可能只是在 Write Through 模式下工作。这是因为安全使用 Write Back 的前提是 RAID 卡有电池备份单元。为了确保电池的有效性,RAID 卡会定期检查电池状态,并在电池电量不足时对其进行充电,在充电的这段时间内会将 Write Back 功能切换为最为安全的 Write Through。
用户可以在没有电池备份单元的情况下强制启用 Write Back 功能,也可以在电池充电时强制使用 Write Back 功能,只是写入是不安全的。用户在启用前应该确认这一点,否则不应该在没有电池备份单元的情况下启用 Write Back。